Original
"A cat wearing a tie."
"A dog."
"A pig."
"A shiba inu."
"A rabbit."
"A raccoon."
"A tiger."
"An owl."
We present Muse, a text-to-image Transformer model that achieves state-of-the-art image generation performance while being significantly more efficient than diffusion or autoregressive models. Muse is trained on a masked modeling task in discrete token space: given the text embedding extracted from a pre-trained large language model (LLM), Muse is trained to predict randomly masked image tokens. Compared to pixel-space diffusion models, such as Imagen and DALL-E 2, Muse is significantly more efficient due to the use of discrete tokens and requiring fewer sampling iterations; compared to autoregressive models, such as Parti, Muse is more efficient due to the use of parallel decoding. The use of a pre-trained LLM enables fine-grained language understanding, translating to high-fidelity image generation and the understanding of visual concepts such as objects, their spatial relationships, pose, cardinality, etc. Our 900M parameter model achieves a new SOTA on CC3M, with an FID score of 6.06. The Muse 3B parameter model achieves an FID of 7.88 on zero-shot COCO evaluation, along with a CLIP score of 0.32. Muse also directly enables a number of image editing applications without the need to fine-tune or invert the model: inpainting, outpainting, and mask-free editing.
Our model generates high-quality images from text prompts fast (1.3s for 512x512 resolution or 0.5s for 256x256 resolution on TPUv4).




Our model gives us zero-shot, mask-free editing for free by iteratively resampling image tokens conditioned on a text prompt.
Original
"A cat wearing a tie."
"A dog."
"A pig."
"A shiba inu."
"A rabbit."
"A raccoon."
"A tiger."
"An owl."





Our model gives us mask-based editing (inpainting/outpainting) for free: mask-based editing is equivalent to generation.
Original (with mask)
"New York in the background"
"Paris in the background"
"San Francisco in the background"





Muse's speed and tokenization approach enables real-time interactive editing of images. For these examples, each update is processed in 760ms via a single pass through the base model and 8 passes through the superres model.
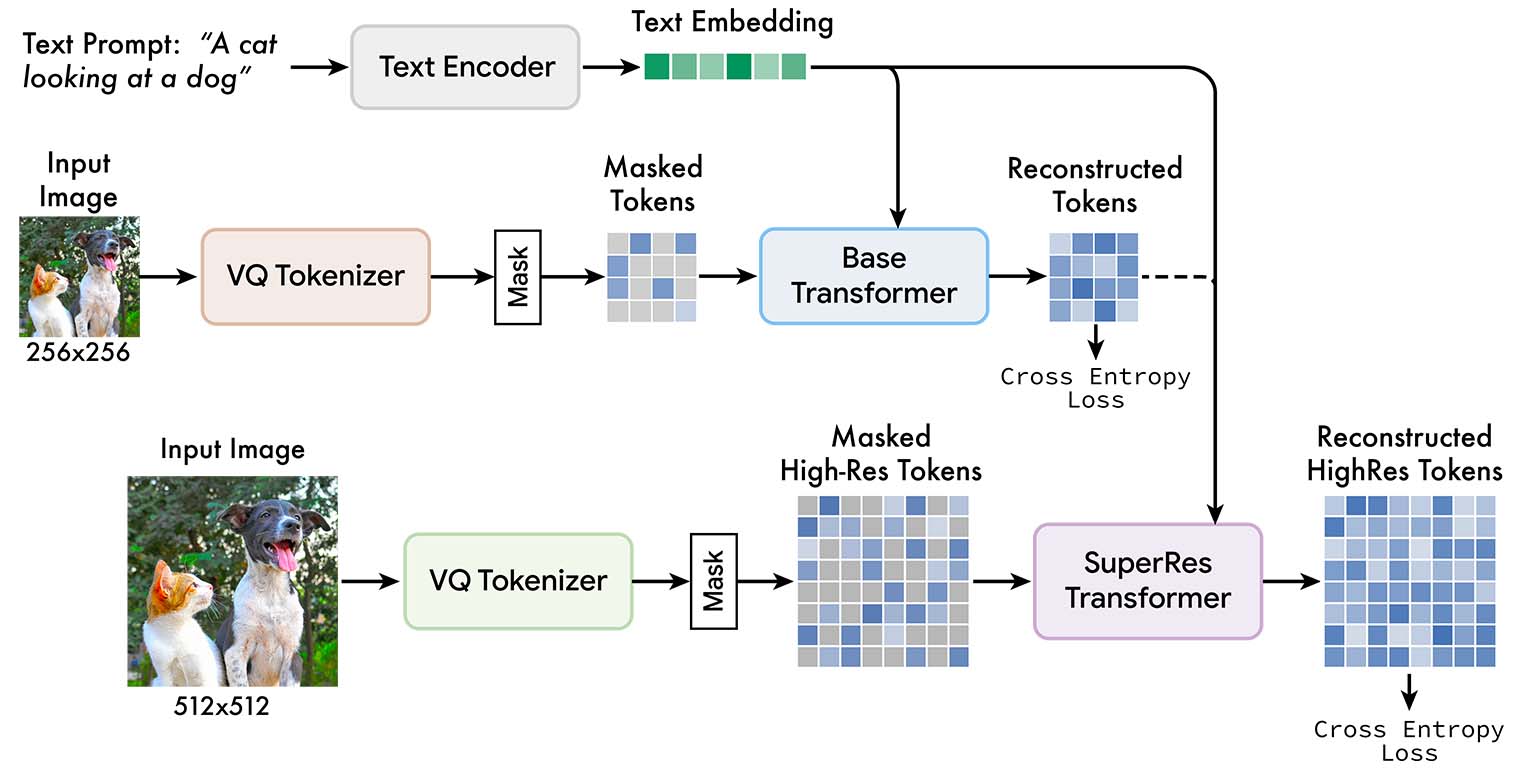
Muse training pipeline. We feed low resolution and high resolution images into two independent VQGAN tokenizer networks. These tokens are then masked, and low resolution ("base") and high resolution ("superres") transformers are trained to predict masked tokens, conditioned on unmasked tokens and T5 text embeddings.
| Model | Resolution | Inference Time (↓) |
|---|---|---|
| Stable Diffusion 1.4* | 512x512 | 3.7s |
| Parti-3B | 256x256 | 6.4s |
| Imagen | 256x256 | 9.1s |
| Imagen | 1024x1024 | 13.3s |
| Muse-3B | 256x256 | 0.5s | Muse-3B | 512x512 | 1.3s |
| Model | FID (↓) | CLIP (↑) |
|---|---|---|
| Stable Diffusion 1.4 | 12.63 | - |
| Parti-3B | 8.10 | - |
| Imagen | 7.27 | 0.27 |
| Muse-3B | 7.88 | 0.32 |